Privacy Enhancing Computing
Professor

Yunheung Paek
Members
Yungi Cho
Woorim Han
Dongju Lee
Youyeon Joo
Heon Hui Jung
Miseon Yu
Sungyeon Lee
Younghan Choe
Jiwan Seo
Eunmin Kim
Hwichan Choo
Current Research
Privacy Preserving Machine Learning
4차 산업혁명의 핵심으로 자리잡은 AI는 주요 산업 뿐 아니라 실생활 속 곳곳에 자리잡아왔다. 꾸준한 연구노력을 통해 AI 모델들은 더욱 높은 정확도를 위해 발전해 왔으며, 일반적으로 모델의 규모가 커지고 대규모 데이터를 학습하는 딥러닝이 대두되었다. 연산 복잡도가 증가한 딥러닝을 감당하기 위해 고성능, 대용량 컴퓨팅 능력이 필요해졌으며, 이에 원격 컴퓨팅의 수요가 증가하였다.
2021년 현재 딥러닝 서비스 플랫폼 중 가장 큰 비중을 차지하는 원격 컴퓨팅은 딥러닝 모델의 고속 연산을 지원하며 실시간 서비스 제공이 가능하고, 계산 장비 유지 보수 비용절감과 높은 접근성을 자랑한다. 이러한 장점을 중심으로 지속적인 연구 노력 속 최근 5년 사이 급격히 정교하고 정확한 AI 서비스들이 등장하기 시작했다. 하지만 클라우드 내부 관리자 등 내부자 위협, 데이터 소실, 변조, 유출 등 위험이 상시 존재하는 원격 컴퓨팅은 사용자들의 데이터를 완벽히 지켜주지 못하였으며, 이에 프라이버시 보존에 대한 필요성이 강조되고 있다.
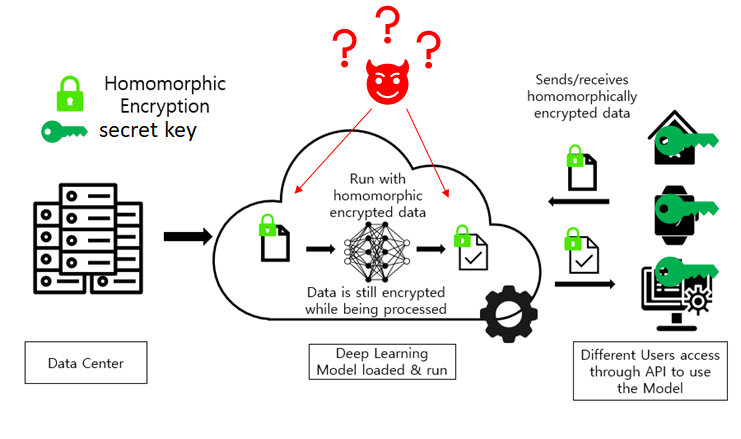
프라이버시 보존을 위한 많은 시도가 이어져 왔으며 K-익명성, 차분 프라이버시, 연합학습 등 다양한 방안들이 제안되었으나 완전한 프라이버시 보존을 이루지 못하거나 정보값을 유실하는 방법들이었기에 완벽한 해답이 되지 못하고 있었으나, 최근 동형암호가 가장 유력한 해답 후보로 등장하였다. 동형암호란 암호화 상태의 데이터를 복호화 없이 연산할 수 있는 암호기술로써, 사용자가 암호화한 데이터를 클라우드로 전송하면 클라우드에서는 암호 상태로 연산하기 때문에, 내부자 위협으로부터 벗어날 수 있고, 돌려받아 복호화하여 값을 확인할 수 있어 사용자 본인만 원문을 열람할 수 있는 체계이다.
프라이버시 보존은 이루었으나 동형암호는 매우 느린 연산량과(IBM의 HeLib은 일반 평문 연산에 비해 50만배 느리다) 큰 메모리 부하(float_64값 하나를 위해 12.5MB의 암호문이 필요하다)가 한계점으로 자리잡고 있다. 또한 일반적으로 비선형 함수 구현이 어렵기 때문에 비선형성이 강조되는 딥러닝 모델 구현에 있어 큰 제한점이 되었다. 이러한 단점을 극복하기 위해 동형암호 연산에 최적화된 하드웨어 모듈, 그리고 이들을 활용한 딥러닝 성능을 높이기 위한 연구의 중요성이 강조되고 있다.
위와 같은 주제와 관하여 우리 연구실은 아래와 같은 연구들을 진행하고 있습니다.
Deep Learning Over Encrypted Data
암호화 상태에서 연산을 진행할 수 있는 동형암호를 딥러닝에 적용시키고, 느린 성능과 메모리 부하라는 단점을 극복하기 위한 HW 가속 연구를 진행하고 있습니다. 이를 위해 다양한 암호 체계에 대한 최적화 연구, 암호 맞춤형 모델에 대한 연구, 이들을 아울러 가속 HW를 구현하는 것을 목표로 하고 있습니다.
Deep Learning over Trusted Execution Environment
Intel SGX와 ARM TrustZone과 같은 신뢰 실행 환경 enclaves들 내에서 딥러닝을 진행하는 연구를 진행하고 있습니다. 상대적으로 작은 TEE를 활용하기 위한 Model Partitioning과 부분적 암호화 등 다양한 방향의 연구를 진행하고 있습니다.
Privacy Preserving AI techniques
현대의 AI 기술은 대규모 데이터의 수집 및 분석을 통해 전례 없는 성능 향상을 이루고 있다. 이러한 발전은 특히 빅데이터를 기반으로 하는 4차 산업혁명 시대에 더욱 두드러지고 있다. 그러나 이러한 데이터 중심의 접근 방식은 최근 강화된 개인정보보호법과 충돌하여 데이터 수집이 어려워지기 때문에 새로운 도전에 직면하고 있다. 이를 해결하기 위해 '연합학습'이라는 새로운 학습 방식이 등장했다.
연합학습은 중앙 집중식 데이터 수집 없이도 학습이 가능하며, 사용자의 프라이버시를 보호하는 동시에 효과적인 학습 결과를 제공하는 실용적인 방법이다. 이 방법은 구글의 Gboard와 애플의 Siri 같은 실제 사례에서 성공적으로 적용되면서 전통적인 AI 학습 방식에 대한 중요한 대안이 되고 있다. 그럼에도 불구하고, 연합학습은 아직 참여자에 의한 보안 위협과 추가적인 프라이버시 유출 문제로 인해 고통받고 있다.
위와 같은 주제와 관하여 우리 연구실은 아래와 같은 연구들을 진행하고 있습니다.
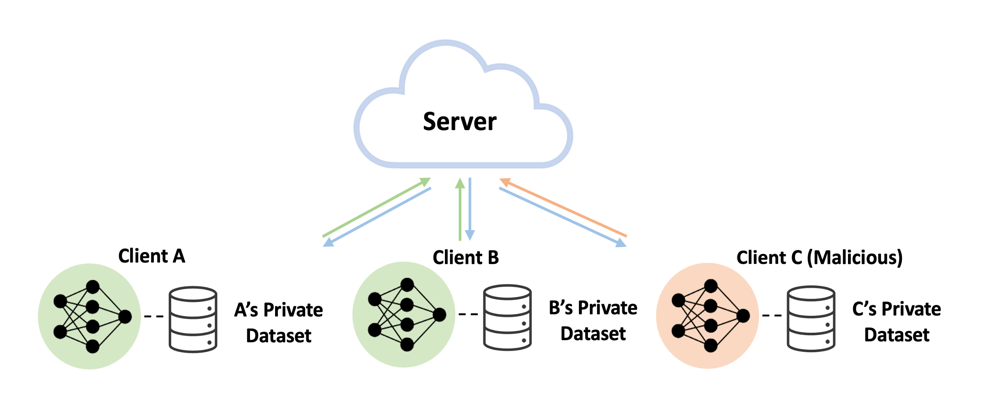
Privacy Concerns in FL
AI 모델은 다양한 프라이버시 위협에 노출되어 있습니다. 대표적으로 데이터의 학습데이터 포함 여부(Membership inference), 학습 데이터 복원(Model Inversion), 의도하지 않은 정보 유출(Property Inference) 등이 존재합니다. 이러한 문제는 연합학습에서도 발견되며, 이러한 문제들에 대한 해결책을 모색하고 있습니다.
Secure and Robust FL
연합학습에서 일부 악의적인 참여자가 학습을 왜곡하여, 컨소시움의 의도와 달리 그들의 의도대로 모델이 동작하도록 모델을 오염시킬 수 있습니다. 이를 해결하기 위해 학습 과정 또는 모델에서 악의적인 참여자의 영향력을 감소시키고 학습 컨소시움을 보호하는 연구를 진행하고 있습니다.