AI Computing
Professor

Yunheung Paek
Members
Hyunjun Kim
Whoi Ree Ha
Current Research
Design Space Exploration
딥러닝과 같은 인공지능 기술이 발전함에 따라 대규모 딥러닝 모델 연산을 처리하기 위한 전용 하드웨어 개발에 대한 경쟁이 매우 치열해지고 있다. 딥러닝 전용 가속기는 연산을 가속하고자 하는 딥러닝 모델에 의존적이며, 효율적인 가속기 개발을 위해 딥러닝 모델과 하드웨어 설계에 대한 사전 지식이 필수적이다. 또한 각 모델에 맞는 딥러닝 전용 가속기를 설계하기 위해서 모델의 이해 및 분석 뿐만 아니라, 모델에 맞는 최적의 HW 구조와 그 HW 구조에 AI 모델을 어떻게 매핑할 것인지를 결정해야 한다. AI 가속기 디자인을 결정짓는 요소로 메모리 구조 및 PE array의 구조가 다양하게 존재하며, 각 HW 구조에 따라 딥러닝 모델이 최적화되어 매핑될 수 있는 방법이 달라진다. 매 딥러닝 모델마다 HW 구조를 설계하고 그에 맞는 매핑을 찾는 것이 쉽지 않기 때문에 이를 자동으로 탐색하려고 하는 연구들이 진행되어 왔고, 해당 기술을 Design Space Exploration (DSE)라고 한다.
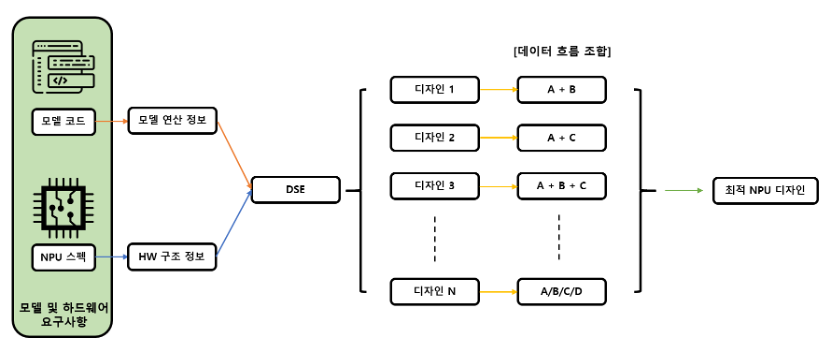
본 연구에서는 특정 딥러닝 모델들이 주어졌을 때 DSE 기술을 활용하여 최적의 가속기를 개발하는 것을 목표로 한다. 우선, 원본 AI 코드에 필요한 연산 요구사항 및 하드웨어 명세 기술을 개발한다. 해당 명세 기술을 기반으로 AI 가속기 구조 및 필요한 AI 연산에 대한 디자인 스페이스를 제한한 다음, 최적 AI 가속기 디자인을 탐색한다. 특히, 다양한 AI 모델 스펙에 맞춰서 이종의 다양한 AI 가속기에 대한 수요가 급증하고 있는데, 이러한 이종 AI 가속기들의 최적 디자인을 탐색하고 이들을 효율적으로 스케쥴링하는 방법에 대한 연구를 진행하고자 한다. 선수과목으로 프로그래밍 방법론, 디지털 시스템 과목을 수강하면 본 프로젝트를 수행에 있어 도움이 되지만, 본 프로젝트를 수행하면서 필요한 지식들을 습득하며 진행할 수 있다.